




Usage
Summary of the main changes in version 3 of the package. RBApy version 3 is a major update, enabling the semi-automatic construction and simulation of RBA models of prokaryotes as well as eukaryotes. Models are saved in the rbaml version 2 format. Older RBA models (encoded in rbaml version 1) are not compatible anymore with RBApy version 3 and need to be updated (see section 1.1). Major changes also include the introduction of macromolecule decay (based on their respective half life times), the ability to define other environmental variables than the medium composition (e.g. temperature) and the capability of predicting growth-optimal compartment sizes. For further information please consult the documentation materials.
Here is the usage for the version 3 of the package, which is capable of generating and simulating RBA models for prokaryotic and eukaryotic cells. For the usage of older versions of the RBApy package, see here.
1. Running an existing model
1.1 How to update an existing model to version 3?
Open a console and run the command line
update-rba-model path/to/model model and outputs) have been created.
The updated xml files of your RBA model are now stored in model, while the results of simulation will be stored
in outputs. In addition, the metadata file (metadata.tsv) and the configuration file
for simulation (model_file_index.in) are also created.
1.2 How to run an existing model?
There are currently several available RBA models (including the ones of Bacillus subtilis and Escherichia coli), and they can be found on our github repository: RBA-models. To run them, or any other existing RBA model, open a console at the root of the RBApy repository, and run:
python solve_rba_model.py path/to/model or use the command line
solve-rba-model path/to/model
where the path points to the directory containing the XML files defining the RBA model.
You can simulate the model with several options:
- --lp-solver : ('cplex', `glpk`, `swiglpk`, ``gurobi``, or `scipy`; 'default: `cplex` if installed, otherwise `gurobi` if installed, otherwise `glpk`)'
- --mu-min : Minimum μ to check; default: 0.0
- --mu-max : Maximum μ to check; default: 2.5
- --bissection-tol : Tolerance for bissection algorithm; default: 1e-4
- --max-bissection-iters : Maximum number of iterations for bissection; default: None
- --output-dir : Directory to save the results; defaut: the directory for the model
- --verbose : Details on the simulation
1.3 How to visualize results of RBApy simulations?
Results of RBApy simulations can be exported in formats supported for visualization of genome-scale flux data with Escher maps and protein data with Proteomaps. To export flux data in a format compatible with Escher maps (JSON), a line can be added to you simulation script:
results.write_fluxes('path_to_file',
file_type='json',
merge_isozyme_reactions=True,
only_nonzero=True,
remove_prefix=True)Click to see an example of fluxes visualized using Escher maps:
The generated file can then be uploaded to Escher maps via their menu Data -> Load reaction data. The function supports json and csv file types. If merge_isozyme_reactions option is set to True, all the reactions which are catalyzed by the same enzymatic function, but of different protein composition are summed up under the original reaction ID (check section 5.2). If the reactions IDs are preceeded by an "R_" prefix, but the visualization tool expects it to be absent, it can be removed by setting the option remove_prefix to True.
Proteome prediction can be visualized via Proteomaps. The file compatible with their input format can be generated by adding this line to your simulation script:
results.write_proteins('path_to_file', file_type='csv')Of course, Proteomaps will be able to visualize your data provided that your proteins are assigned KEGG IDs. In case other ID types are used, RBApy doesn't convert them to KEGG IDs. This has to be taken care of by the user.
Click to see an example of protein concentrations visualized using Proteomaps:
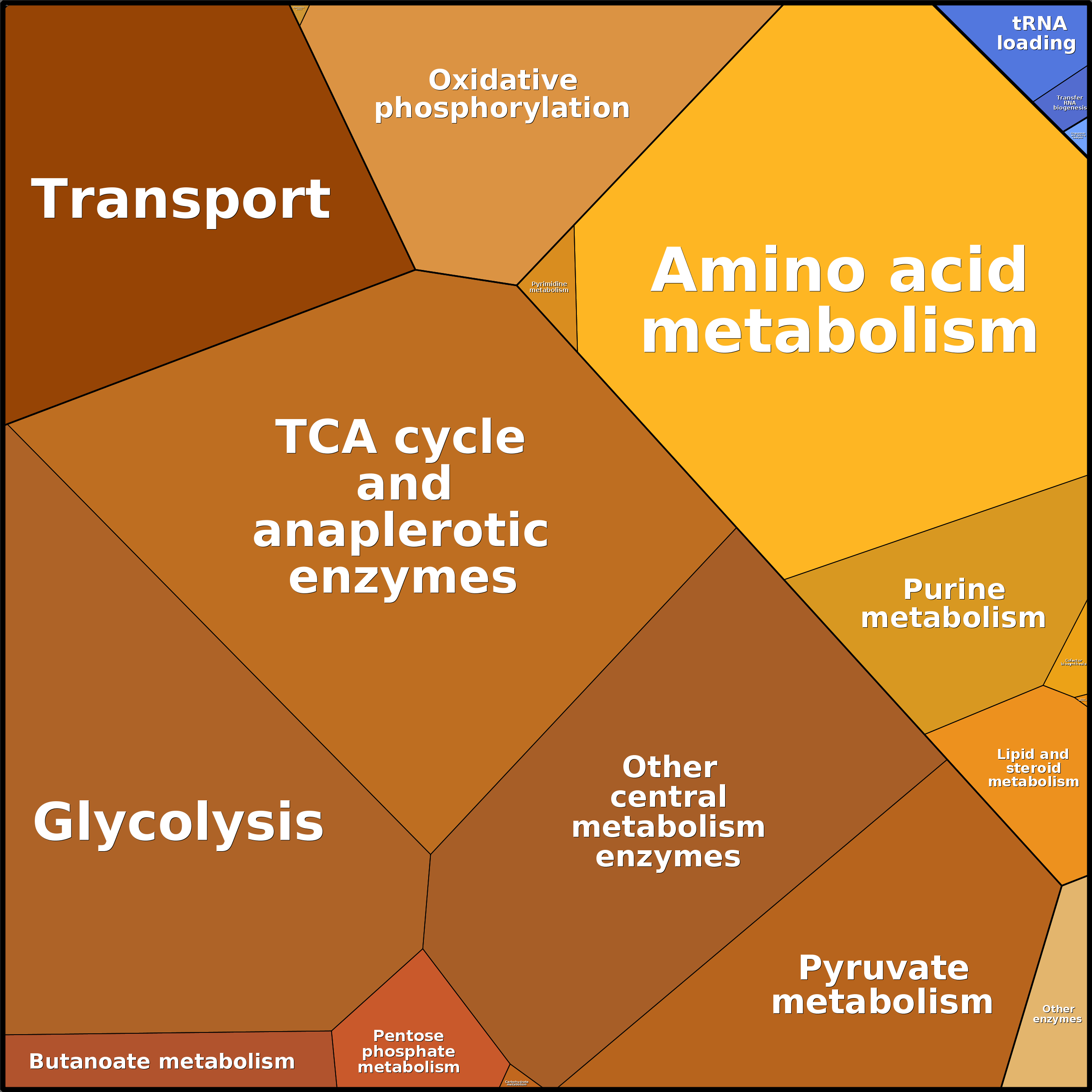
1.4 How to change the medium and environmental variables?
The medium composition and environmental variables (such as temperature) are defined in the file medium.tsv. The file is located in the directory containing the XML files defining the RBA model. The first column contains the prefixes of metabolites that are detected in the external compartments in the SBML (see section 5.1). The second column corresponds to the concentration of metabolites in millimoles. The other columns (named Type, Unit and Comment) contain metadata. Type detail if the variable is a Chemical Specie or an Environmental variable. Unit contains the unit, and Comment is a free text.
To change the medium composition:
- Open the file medium.tsv defining the medium composition.
- Update the metabolite concentration as follows:
--------------------------------
Original file
--------------------------------
Metabolite Concentration Type Unit Comment
M_k 10 Chemical species mmol/l Boundary metabolite from SBML
M_no3 10 Chemical species mmol/l Boundary metabolite from SBML
Temperature 37 Environmental variable Celsius Temperature of the room
etc.
--------------------------------
New file
--------------------------------
Metabolite Concentration Type Unit Comment
M_k 10 Chemical species mmol/l Boundary metabolite from SBML
M_no3 5 Chemical species mmol/l Boundary metabolite from SBML
Temperature 37 Environmental variable Celsius Temperature of the room
etc.
python solve_rba_model.py path/to/model Here RBApy evaluates the apparent catalytic rates of transporters using the new metabolite concentrations, before solving the optimization problem.
1.5 Can I change my model parameters?
RBA model parameters are defined in the file parameters.xml. This file is located in the directory containing the XML files of the RBA model.
To update parameters Open the file parameters.xml and update the value of the parameter that you want to change. For instance:
--------------------------------
Original file:
the function ribosomeEfficiencyMM describing the efficiencies of ribosomes
max(Ymin, kmax*µ/(Km+µ))
--------------------------------
<function id="ribosomeEfficiencyMM" type="michaelisMenten">
<listOfParameters>
<parameter id="kmax" value="97200"/>
<parameter id="Km" value="0.5"/>
<parameter id="Y_MIN" value="32400"/>
</listOfParameters>
</function>
etc. Change the maximal rate of translation from 97200 aa/h to 48600 aa/h:
--------------------------------
New file:
the function ribosomeEfficiencyMM describing the efficiencies of ribosomes
max(Ymin, kmax*µ/(Km+µ))
--------------------------------
<function id="ribosomeEfficiencyMM" type="michaelisMenten">
<listOfParameters>
<parameter id="kmax" value="48600"/>
<parameter id="Km" value="0.5"/>
<parameter id="Y_MIN" value="32400"/>
</listOfParameters>
</function>>Run the model using the command line or:
python solve_rba_model.py path/to/model Here RBApy will automatically read the new values. For the units of all parameters, please refer to the paper Goelzer et al. 2015, or to the description of the XML format defining RBA models.
Be careful when you update some parameters! Some parameters such as the fraction of total proteins allocated to the different compartments must sum to 1. The fraction of non-enzymatic proteins within compartments should be lower than 1.
2. Creating a new RBA model
2.1 What do I need to create a new RBA model?
To create your own RBA model, you need the full rbapy package, and:- The NCBI taxon ID of your organism (e.g. 83333 for Escherichia coli K-12)
- a valid SBML file for the same organism (see requirements in section 5.1).
2.2 How to create my new RBA model?
Define one input directory and put the SBML file, the fasta files in this directory.
Fill in the configuration file called input/params.in, where you will specify the taxon ID, the organism type
('prokaryote', 'eukaryote_with_chloroplast', 'eukaryote_without_chloroplast') for selecting the relevant set of default processes,
the path to the input and output directories, the name of the SBML file, and the external compartments of the SBML file.
Examples of input directories and of configuration files are provided in the directory called sample_input in the RBApy repository on Github.
python generate_rba_model.py path/to/params.ingenerate-rba-model path/to/params.in- several XML files describing the RBA model. They are located in the output directory specified in params.in
- several CSV Helper files (see section 5.3) containing default values for ambiguous information (e.g. cofactor IDs which couldn’t automatically be linked to model metabolites). They are located in the input directory, with your SBML and fasta files.
Remark: RBApy creates automatically two versions of the RBA model: one that integrates explicitly one reaction per catalyzing isoenzymes (see section 4.1), and one where all isoenzymes are pooled in a mean enzymatic complex for each reaction. Both models can be run (see section 1.2).
2.3 How to refine my RBA model?
After the first run of model generation, one has:- several XML files describing the RBA model. They are located in the output directory specified in params.in
- several CSV Helper files (see section 5.3) containing default values for ambiguous information (e.g. cofactor IDs which couldn’t automatically be linked to model metabolites). They are located in the input directory, with your SBML and fasta files.
- Edit manually the XML files (not recommended)
- Edit manually the fasta files and the helper files, fill them in with information and re-run the model generation using the command line or:
python generate_rba_model.py path/to/params.in- Update the helper file unknown_proteins.tsv (section 2.3.3.7)
- Update the helper file location_map.tsv (section 2.3.3.3)
- Update the helper file gene_location.tsv (section 2.3.3.4)
- Update the helper file metabolites.tsv (section 2.3.3.1)
- Update the optional helper file macrocomponents.tsv (section 2.3.3.2)
- Update helper files specific to proteins: protein_curation.tsv (section 2.3.3.5) and cofactors.tsv (section 2.3.3.6)
- Update the fasta files with user-defined molecular machineries (section 2.3.2)
- Update the cellular processes (section 2.3.1)
python generate_rba_model.py path/to/params.in python solve_rba_model.py path/to/model2.3.1 Update of cellular processes
During the first run of RBApy, the package will use a set of default processes depending on the type of organism:
- prokaryotes: replication, transcription, translation, folding, RNA and protein degradation, and using the ribosome composition, the average chaperone composition and the tRNAs of Escherichia coli.
- eukaryotes_without_chloroplast: replication, transcription, translation, folding, RNA and protein degradation, protein translocation in cellular organelles, and using the machinery composition, and tRNAs of Saccharomyces cerevisiae.
- eukaryotes_with_chloroplast: replication, transcription, translation, folding, RNA and protein degradation, protein translocation in cellular organelles, and using the machinery composition, and tRNAs of Arabidopsis thaliana.
The default cellular processes are defined with the file process_definition.tsv, which needs to be updated with new cellular parocesses. process_definition.tsv contains ten columns:
- MACROMOLECULE TYPE: the type of processed molecule by the cellular process: dna, rna or protein.
- ID: located individual protein identifiers to be added to the process
- ORIGIN: the cellular location where the molecule is originally produced using the RBA compartments (see 2.3.3.3)
- LOCATION: the cellular location of the molecule using the RBA compartments (see 2.3.3.3)
- PROCESS: the name of the cellular process, which must be the same as the name of the fasta file (see 2.3.2)
- CAPACITY PARAMETER: the capacity coefficient of the process, which has to be present in parameters.xml
- PROCESSING LOCATION: the cellular location of the cellular process using the RBA compartments (see 2.3.3.3)
- PROCESSING TYPE: the type of cellular process: production or degradation
- TEMPLATE PROCESSING MAP: the processing map that is associated to the process. RBApy provides seven different default processing maps for translation (default_translation), transcription, (default_transcription), replication (default_dna_replication), rna and protein degradation (default_rna_degradation, default_protein_degradation), for translocation and folding (default_processing and default_processing_atp_dependent)
- INPUT FRACTION: a coefficient (set to 1 by default) applied to all processed molecule.
The columns MACROMOLECULE TYPE, ID, ORIGIN and LOCATION are used to automatically build the list of processed molecules for each process. For instance, if MACROMOLECULE TYPE, ORIGIN and LOCATION are set to protein, Nucleus and Plastid respectively, RBApy will automatically create a list of proteins present in the model that are encoded in the Nucleus and located in the Plastid. The user needs to create as many lines as there are different lists of processed molecules per cellular process. The column ID allows individual proteins to be added.
The default processing maps assume default processing costs per map, that can be manually updated in processes.xml.
2.3.2 Insertion of user-defined molecular machineries
During the first run of RBApy, the package will use a set of default processes depending on the type of organism:
- prokaryotes: replication, transcription, translation, folding, RNA and protein degradation, and using the ribosome composition, the average chaperone composition and the tRNAs of Escherichia coli.
- eukaryotes_without_chloroplast: replication, transcription, translation, folding, RNA and protein degradation, protein translocation in cellular organelles, and using the machinery composition, and tRNAs of Saccharomyces cerevisiae.
- eukaryotes_with_chloroplast: replication, transcription, translation, folding, RNA and protein degradation, protein translocation in cellular organelles, and using the machinery composition, and tRNAs of Arabidopsis thaliana.
An example: the ribosome machinery. The ribosome is usually composed of 3rRNAs (5S, 15S, 23S), around 50 ribosomal proteins, and the initiation, elongation and release factors. The ribosome.fasta lists all the machinery composition in a pseudo-fasta format:
>rba|rrnO-16S|rrnO-16S|rna|Cytoplasm|Cytoplasm|1
TTTATCGGAGAGTTTGATCCTGGCTCAGGACGAACGCTGGCGGCGTGCCTAATACATGCA
AGTCGAGCGGACAGATGGGAGCTTGCTCCCTGATGTTAGCGGCGGACGGGTGAGTAACAC
GTGGGTAACCTGCCTGTAAGACTGGGATAACTCCGGGAAACCGGGGCTAATACCGGATGG
TTGTTTGAA …
>rba|rrnO-23S|rrnO-23S|rna|Cytoplasm|Cytoplasm||1
GGTTAAGTTAGAAAGGGCGCACGGTGGATGCCTTGGCACTAGGAGCCGATGAAGGACGGG
ACGAACACCGATATGCTTCGGGGAGCTGTAAGCAAGCTTTGATCCGGAGATTTCCGAATG
GGGAAACC …
>rba|rrnO-5S|rrnO-5S|rna|Cytoplasm|Cytoplasm|1
TTTGGTGGCGATAGCGAAGAGGTCACACCCGTTCCCATACCGAACACGGAAGTTAAGCTC
TTCAGCGCCGATGGTAGTCGGGGGTTTCCCCCTGTGAGAGTAGGACGCCGCC
>rba|P0AG67|RS1_ECOLI 30S ribosomal protein S1 OS=Escherichia coli (strain K12) GN=rpsA PE=1 SV=1|protein|Cytoplasm|Cytoplasm|1
MTESFAQLFEESLKEIETRPGSIVRGVVVAIDKDVVLVDAGLKSESAIPAEQFKNAQGEL
EIQVGDEVDVALDA…
…>rba | Molecule ID | Molecule Name | Molecule Type | Molecule Origin | Molecule Location | Molecule Stoichiometry
--- Sequence ----
- rba: means that this entry corresponds to RBA machinery
- Molecule ID: The identifier of the molecules. For proteins, the ID must corresponds either to the Uniprot Protein, either to one of the gene names.
- Molecule Name: the name of the molecule.
- Molecule Type: the Type of the molecule. Type can take two values: protein, rna. See below. The molecule type enables to insert automatically the new molecule in proteins.xml and rnas.xml, and also in processes.xml, within the list of production of processes that target molecules of same Type
- Molecule Origin: the cellular location where the molecule is originally produced using the RBA compartments (see 2.3.3.3)
- Molecule Location: the cellular location of the molecule using the RBA compartments (see 2.3.3.3)
- Molecule Stoichiometry: the stoichiometry of the molecule within the molecular machine.
During the parsing of the fasta file, each time a protein is read, RBApy automatically assign the location of the protein to the value in 'Molecule Location', and tries to extract automatically the cofactors (see 2.3.3.5) of the protein. In case of ambiguities, the protein is also inserted in the file cofactors.tsv. If the protein is not present in the uniprot file, the protein is still inserted in proteins.xml using the amino-acid sequence of the fasta file, and in processes.xml. By default, the protein will be located in the cytoplasm, without cofactors. Moreover, the unknown protein is also inserted in the file unknown_proteins.tsv (see 2.3.3.7).
An advice: For the ID of proteins, we recommend to use either the Uniprot protein ID (e.g. P21464), either the absolute identifier of the gene name (e.g. BSU16490), but not the gene name in 4 letters (e.g. rpsB). Indeed, the field gene name in Uniprot contains the current gene name of the protein, but also all synonyms. Sometimes, some genes may have been renamed, which can result in multiple entries for the 4-letters gene name.
To update the RBA model, re-run the model generation using the command line orpython generate_rba_model.py path/to/params.in- proteins.xml which contains the new proteins of the molecular machine.
- rnas.xml which contains the new rnas of the molecular machine
- processes.xml where the new proteins have been included in the processes “Translation”, “Folding”, "Protein degradation" and the new rnas in the processes “Transcription” and “RNA degradation”
2.3.3 Helper files
2.3.3.1 Metabolites.tsv
The file metabolites.tsv is critical for RBApy. First It identifies metabolic precursors that are consumed/produced by the cellular processes to build biomass component. Second, the file is also used to link these metabolic biobricks to SBML ids of metabolites from the metabolic network.
In metabolites.tsv, the user declare:- M1: All metabolic precursors that are consumed/produced by the cellular processes to build proteins, RNAs, DNAs. A minima, RBApy expects to find the metabolic precursors involved in the default processes: Replication, Transcription, Translation, Folding, RNA and protein degradation, which are: all amino acids, all charged/uncharged tRNAs, NMP, NDP, NTP, dNTP, water, protons, mono- and di-phosphate.
For eukaryotic cells, one cellular process (such as the translation) can occur in several cellular compartments.
Therefore, RBApy tries to detect common SBML IDs without the location suffix for these precursors, e.g. M_trnaala instead of M_trnaala_c, namely:
- M_trnaala, M_trnaarg, ..., M_trnaval for uncharged tRNAs
- M_alatrna, M_argtrna, ..., M_valtrna for charged tRNAs
- M_ATP, M_GTP, M_CTP, M_UTP, for ATP, GTP, CTP and UTP respectively
- M_ADP, M_GDP, M_CDP, M_UDP, for ADP, GDP, CDP and UDP respectively
- M_AMP, M_GMP, M_CMP, M_UMP, for AMP, GMP, CMP and UMP respectively
- M_h2o, M_h, M_p, M_pp for water, proton, mono- and di-phosphate respectively
- M2: All ions/cofactors required to have the active form of a protein. The ions and cofactors are automatically extracted from the Uniprot annotation (see section 2.3.2.5) and reported in metabolites.tsv for ID matching.
- M3: All metabolites for which the intracellular concentration is growth-rate independent, and the value of this concentration. The set of growth-rate independent metabolites includes building blocks for cell wall and membrane synthesis, a few metabolites such as co-enzyme A. Usually these metabolites are present in the biomass reaction of the SBML file. Exclude all metabolites from the set M1 and M2 from the biomass reaction. The remaining ones form the set M3. The targeted concentrations correspond to the stoichiometric coefficients of the biomass reaction of the SBML file.
The file metabolites.tsv, is organized in 5 columns, entitled ID, NAME, SBML ID, STOICHIOMETRY and CONCENTRATION.
- ID: is the absolute identifier of the metabolite, which can be the ChEBI
- NAME: the name of the metabolite
- SBML ID: the SBML identifier without the location suffix corresponding to the metabolite, present in the genome-scale metabolic model
- STOICHIOMETRY: the stoichiometry to be applied, e.g. 2Fe-2S requires 2 molecules of iron per 2Fe-2S cluster
- CONCENTRATION: the concentration of growth-rate independent metabolite
python generate_rba_model.py path/to/params.inNow look at the files
- processes.xml: The lists of of metabolic precursors used in cellular processes are updated
- targets.xml: The targeted group named "metabolite_production" is updated with the set of metabolite M3, and their targeted concentrations are reported in the file parameters.xml.
2.3.3.2 Macrocomponents.tsv (optional)
The file macrocomponents.tsv describes the metabolic requirements to build macro-components such as the cell wall or the cytoplasmic membrane. Usually, the intracellular concentration of such macro-components is growth-rate independent. The file describes which metabolite is required for macro-component synthesis, and the value of this concentration.
The file is organized in two columns, TARGET_METABOLITE and TARGET_FLUX.
- TARGET_METABOLITE: the SBML ID (including the location id) of the metabolic precursor necessary to build the macro-component
- TARGET_CONCENTRATION: the value C of the targeted concentration
To update the RBA model, re-run the model generation using the command line or
python generate_rba_model.py path/to/params.in2.3.3.3 Location_map.tsv
The file location_map.tsv is used to link protein annotation (e.g Unitprot) and SBML location ids with user-defined compartment ids. This file is critical to enable the mapping between the metabolic model, protein annotation and RBA. For every protein annotation and SBML location, user may fill in a RBA compartment name. The idea behind this file is that it can be used to fuse compartments or ignore them. If the field is left empty (or [MISSING]), a compartment named after the protein annotation location is created.
Location_map.tsv contains three columns:
- DATA LOCATION: the location names extracted from the SBML file, proteome_annotation.tsv, the location of user-defined machineries
- RBA LOCATION: the name of the location used in RBA
- DATA TYPE: can take SBML, GENOME LOCATION, FASTA MACHINERY or ANNOTATION PROTEOME to indicate the information source of the location. This column is only indicative and for tracability.
An example:
| DATA LOCATION | RBA LOCATION | DATA TYPE |
| Cell outer membrane | Cell_outer_membrane | ANNOTATION PROTEOME |
| Cell inner membrane | Cell_inner_membrane | ANNOTATION PROTEOME |
| Cytoplasm | Cytoplasm | ANNOTATION PROTEOME |
| Cell membrane | Cell_inner_membrane | ANNOTATION PROTEOME |
| Periplasm | Periplasm | ANNOTATION PROTEOME |
| Membrane | Cell_inner_membrane | ANNOTATION PROTEOME |
| Secreted | Secreted | ANNOTATION PROTEOME |
| e | Secreted | SBML |
| c | Cytoplasm | SBML |
| e,p | Cell_outer_membrane | SBML |
| c | Cytoplasm | SBML |
| p,c | Cell_inner_membrane | SBML |
| p | Periplasm | SBML |
To update the RBA model, re-run the model generation using the command line or
python generate_rba_model.py path/to/params.in <RBACompartments>
<listOfCompartments>
<compartment id="Cell_inner_membrane"/>
<compartment id="Cytoplasm"/>
<compartment id="Cell_outer_membrane"/>
<compartment id="Periplasm"/>
<compartment id="Secreted"/>
</listOfCompartments>
</RBACompartments>
2.3.3.4 Gene_locations.tsv
gene_locations.tsv contains the cellular location of the chromosome where the gene belongs and using the RBA compartments (see 2.3.3.3). RBApy extracts automatically all genes of the SBML model to feed this helper file. The file contains two columns
- GENE ID: the gene ID of the SBML model
- GENOME LOCATION: the cellular location of the chromosome where the gene belongs and using the RBA compartments (see 2.3.3.3).
2.3.3.5 Protein_curation.tsv
Protein_curation.tsv contains the information used by RBApy to determine individual protein location and subunit structure.
It also allows to disable some genes when generating context-specific RBA models.
Location: In the version 1 of the package, RBApy used only the Uniprot location (from the field SUBCELLULAR LOCATION [CC] of protein_annotation.tsv) to determine the protein location.
Now, the protein location is automatically determined from the location of the metabolic reaction for metabolic enzymes, and from the user-defined machinery (see section 2.3.2).
Additionaly, the Uniprot location is also reported for protein location checking. A
IMPORTANT: After model generation, the protein identifier used in proteins.xml and
enzymes.xml will be updated with a location tag (see the example below).
Subunits: RBApy parses automatically the field SUBUNIT STRUCTURE [CC] of protein_annotation.tsv to determine the stoichiometry of a protein within its enzymatic complex.
For every ambiguous and empty entry, gene name and protein name are provided for proper identification.
By default, the stoichiometry of the protein is set to 1.
User should read annotation field (or any other sources of information) and update the stoichiometry and the location if necessary.
The file protein_curation.tsv contains 13 columns, named
- GENE: the gene ID of the protein belonging to an enzymatic complex
- DISABLED: takes the value of 1 (gene is included) or 0 (gene is removed)
- STOICHIOMETRY: the stoichiometyry of the protein within its complex. By default, 1 is set.
- REACTION: the reaction catalyzed by the enzymatic complex in the SBML file
- SUBUNIT: the subunit name of the enzymatic complex
- ISOENZYMES: the list of isoenzymes associated to REACTION where the protein is involved
- RBA LOCATION: the location of the protein using the RBA compartments (see 2.3.3.3). By default, this column is set to LOCATION OF SBML REACTION.
- STOICHIOMETRY REVIEW CODE: score for tracking the source of stoichiometry information. Score 0: Stoichiometry was in annotation and reported in STOICHIOMETRY; Score 1: Stoichiometry was in annotation and but not reported in STOICHIOMETRY (due to manual curation) Score 2: Stoichiometry was not in annotation and a user-defined value is reported in STOICHIOMETRY (due to manual curation). Score 3: Stoichiometry was not in annotation and a stoichiometry default value of 1 is reported in STOICHIOMETRY
- LOCATION REVIEW CODE:score for detecting conflicts between locations in SBML and protein annotation (Score 0: No conflicts; Score 1: The locations inferred from different sources are unequal Score 2: The effective protein location is not equal to location inferred from metabolite locations and not among locations inferred from annotation Score 3: The effective protein location is not equal to location inferred from metabolite locations and not among locations inferred from annotation and the two information sources counterdict each other
- ID IN ANNOTATION: Uniprot ID of protein from protein_annotation.tsv
- LOCATION OF SBML REACTION: the location of the protein determined from the location of the metabolic reaction using the RBA compartments
- LOCATION FROM ANNOTATION: the list of potential protein locations extracted from the parsing of RAW LOCATION FROM ANNOTATION, and converted into RBA compartments using the location_map.tsv
- RAW LOCATION FROM ANNOTATION: the field SUBCELLULAR LOCATION [CC] from protein_annotation.tsv
- RAW SUBUNIT STRUCTURE FROM ANNOTATION: the field SUBUNIT STRUCTURE [CC] from protein_annotation.tsv
To update the RBA model, re-run the model generation using the command line or
python generate_rba_model.py path/to/params.inLet us take the example of the protein b4358 that is located in the periplasm. Look at the file proteins.xml that contains the localisation and composition in amino-acids and cofactors of proteins. The gene identifier and the attribute "compartment" are updated with the new localisation of the protein.
<macromolecule id="b4358_loc_Periplasm" compartment="Periplasm" half_life="default_protein_half_life">
<composition>
<componentReference component="A" stoichiometry="39"/>
<componentReference component="C" stoichiometry="8"/>
<componentReference component="E" stoichiometry="20"/>
<componentReference component="D" stoichiometry="16"/>
<componentReference component="G" stoichiometry="32"/>
<componentReference component="F" stoichiometry="13"/>
<componentReference component="I" stoichiometry="26"/>
<componentReference component="H" stoichiometry="9"/>
<componentReference component="K" stoichiometry="16"/>
<componentReference component="M" stoichiometry="8"/>
<componentReference component="L" stoichiometry="24"/>
<componentReference component="N" stoichiometry="14"/>
<componentReference component="Q" stoichiometry="17"/>
<componentReference component="P" stoichiometry="19"/>
<componentReference component="S" stoichiometry="13"/>
<componentReference component="R" stoichiometry="15"/>
<componentReference component="T" stoichiometry="16"/>
<componentReference component="W" stoichiometry="2"/>
<componentReference component="V" stoichiometry="28"/>
<componentReference component="Y" stoichiometry="5"/>
<componentReference component="CHEBI:29105" stoichiometry="2"/>
</composition>
</macromolecule><enzyme id="R_ATPS4rpp_enzyme" reaction="R_ATPS4rpp" forward_efficiency="R_ATPS4rpp_efficiency" backward_efficiency="default_transporter_efficiency" zeroCost="false">
<machineryComposition>
<listOfReactants>
<speciesReference species="b3734_loc_Cell_membrane" stoichiometry="3.0" comment="SU_1"/>
<speciesReference species="b3732_loc_Cell_membrane" stoichiometry="3.0" comment="SU_2"/>
<speciesReference species="b3731_loc_Cell_membrane" stoichiometry="1.0" comment="SU_3"/>
<speciesReference species="b3733_loc_Cell_membrane" stoichiometry="1.0" comment="SU_4"/>
<speciesReference species="b3735_loc_Cell_membrane" stoichiometry="1.0" comment="SU_5"/>
<speciesReference species="b3737_loc_Cell_membrane" stoichiometry="10.0" comment="SU_6"/>
<speciesReference species="b3736_loc_Cell_membrane" stoichiometry="2.0" comment="SU_7"/>
<speciesReference species="b3738_loc_Cell_membrane" stoichiometry="1.0" comment="SU_8"/>
<speciesReference species="b3739_loc_Cell_membrane" stoichiometry="0.1" comment="SU_9"/>
</listOfReactants>
</machineryComposition>
</enzyme>2.3.3.6 Cofactors.tsv
RBApy parses automatically the field COFACTOR of the Uniprot file to determine the cofactors of a protein. However, the field COFACTOR is often written in natural language, which can lead to difficulties during the parsing. Therefore, for every protein having ambiguities, the file cofactors.tsv lists name, chebi identifier and stoichiometry of cofactors per protein. If one protein has several cofactors, several lines corresponding to the protein are present in cofactors.tsv. Based on the last column (containing uniprot cofactor annotation), user should check inferred values and fill in fields tagged as [MISSING]. Important: if annotation says that there is no cofactor, do not remove line from csv file. Ignore name and chebi fields and set stoichiometry to 0.
The file cofactors.tsv contains 5 columns:
- ENTRY: Uniprot ID of the protein
- CHEBI: ChEBI ID of the cofactor
- NAME: Name of the cofactor
- STOICHIOMETRY : stoichiometry of the cofactor for 1 protein
- UNIPROT ANNOTATION: copy of the field COFACTOR of the Uniprot file
Here is the example of the protein P0ACC7 (Uniprot ID) for which the field COFACTOR cannot be automatically parsed. The following entries are automatically inserted in the file cofactor.tsv. The user must indicate which cofactor the protein will use:
| ENTRY | CHEBI | NAME | STOICHIOMETRY | UNIPROT ANNOTATION |
| P0ACC7 | CHEBI:18420 | Mg(2+) | 1 | Binds 1 Mg(2+) ion per subunit (PubMed:17473010). Can also use Co(2+) ion to a lesser extent (PubMed:11329257). {ECO:0000269|PubMed:11329257, ECO:0000269|PubMed:17473010}; |
| P0ACC7 | CHEBI:48828 | Co(2+) | 0 | Binds 1 Mg(2+) ion per subunit (PubMed:17473010). Can also use Co(2+) ion to a lesser extent (PubMed:11329257). {ECO:0000269|PubMed:11329257, ECO:0000269|PubMed:17473010}; |
To update the RBA model, re-run the generation using the command line or
python generate_rba_model.py path/to/params.inNow look at the file proteins.xml that contains the localisation and composition in amino-acids and cofactors of proteins. The cofactor and its stoichiometry are added (In the example, the protein entry "P0ACC7" corresponds to the gene name "b3730"):
<macromolecule id="b3730_loc_Cytoplasm" compartment="Cytoplasm" half_life="default_protein_half_life">
<composition>
<componentReference component="A" stoichiometry="45"/>
<componentReference component="C" stoichiometry="4"/>
<componentReference component="E" stoichiometry="26"/>
<componentReference component="D" stoichiometry="29"/>
<componentReference component="G" stoichiometry="49"/>
<componentReference component="F" stoichiometry="7"/>
<componentReference component="I" stoichiometry="30"/>
<componentReference component="H" stoichiometry="12"/>
<componentReference component="K" stoichiometry="25"/>
<componentReference component="M" stoichiometry="9"/>
<componentReference component="L" stoichiometry="45"/>
<componentReference component="CHEBI:18420" stoichiometry="1.0"/>
<componentReference component="N" stoichiometry="24"/>
<componentReference component="Q" stoichiometry="20"/>
<componentReference component="P" stoichiometry="13"/>
<componentReference component="S" stoichiometry="11"/>
<componentReference component="R" stoichiometry="24"/>
<componentReference component="T" stoichiometry="30"/>
<componentReference component="W" stoichiometry="3"/>
<componentReference component="V" stoichiometry="39"/>
<componentReference component="Y" stoichiometry="11"/>
</composition>
</macromolecule>2.3.3.7 Unknown_proteins.tsv
The file unknown_proteins.tsv contains the gene names for which the automatic matching between the SBML IDs and either the user-defined protein IDs in the fasta files, either the gene name in the protein annotation file failed. By default, RBApy associates a default protein of mean composition, named "average_protein". However, the user can choose to associate another average protein, or another gene name, as soon as the gene name ID is present in the protein annotation file.
The file unknown_proteins.tsv contains two columns:
- GENE ID SBML: the gene name ID of the SBML file that could not be matched
- GENE ID ANNOTATION: the gene name that will be associated to the SBML gene name. By default, the value is assigned to "average_protein".
To update the RBA model, re-run the model generation using the command line or
python generate_rba_model.py path/to/params.in3. Calibrating an RBA model
An existing RBA model can be calibrated using the RBApy.estim package, which containts a number of scripts.
prot_per_compartment.py is a script allowing one to estimate the percentage of protein allocated to each compartment of the organism.
nonenz_per_compartment.py uses the functional annotations of proteins, such as COG, to estimate the portion of protein in each compartment
which is non-enzymatic. Nonenzymatic proteins can be considered those that do not perform a function within the model (they are not assigned either
to metabolic enzymes or to other molecular machines).
kapp.py allows for the estimation of apparent catalytic rates of enzymes from fluxomics and proteomics experiments performed
in sufficiently similar conditions.
Since the calibration is both model and data dependent, no command line has been implemented. To use the RBApy.estim package, the user must clone the RBApy repository and customize the scripts and configuration files that are available in the estim package. We also provide examples of data files that are called by the configuration files.
3.1 Calibration configuration files
All the calibration scripts make use of configuration files, in a format that is expected from the Python's standard configuration parser.
Examples of these files are available at the RBApy github repository.
All the files that are passed to the calibration scripts need to be either in csv or in some type of Excel format. This is specified via the file_type value, which can take on csv or excel values.
For example, in specifying the file with experiment details, in the case we are providing it in csv format, the configuration would look as follows:
[Experiment]
file = /path/to/file
file_type = csv
delimiter = ;
...If you would want to provide the data in excel format, the configuration would look something like this:
[Experiment]
file = /path/to/file
file_type = excel
delimiter = ;
sheet_name = Sheet1
skiprows = 3
...3.2 Estimating protein percentage per compartment
In order to estimate the protein percentage per compartment, the user needs to have at her disposal a proteomics experiments for cells at different growth rates, and proteins need to have subcellular location annotation. All this information is given to the script via the configuration file prot_per_compartment.cfg.
The configuration script has five fields:
[Experiment]: a csv/excel file which lists the IDs of experiments in one column, and associated growth rates in the other. The expriment IDs need to match ones in the proteomics files. The experiment IDs are expected to be in the first column, and you need to provide the name of the column containing growth rates in the configuration file, under the namegrowth_rate_column.[ProteinData]: a csv/excel file containing measured protein abundances. All experiments are expected to be in the same file (in case of csv) or on the same sheet (in the case of an excel file). If the location data is present in the same sheet, you can additionally provide the parameterlocation column. If not, you can separately fill out the configuration for the subcellular location information.[LocationData]: a csv/excel file containing protein IDs in the first column and subcellular locations in one of the other columns. Multiple locations of one protein have to be entered using the comma separator. User needs to provide the column name inlocation_columnparameter.[CompartmentMap]: a csv/excel file you can use to map multiple compartments onto one. For example, in E. coli, there are comartments called "Outer membrane" and "Cell outer membrane", which can logically be mapped onto one single compartment. This file is for such a purpose. First column should contain the original compartments, and one other column needs to contain the new compartments. The name of this column needs to be supplied in thecm_columnparameter.[Output]: the results of the fitting with be outputted to this file. It requires you to give path to a file, a file type and file type - specific parameters.
0.7 - 0.1 μ, and the minimum and maximum growth rate available for experimental data were 0.2 and 2 [1/h], this information should be inputted into the parameters.xml file of RBA in the following way:
<function id="fraction_protein_Cytosol" type="linear" variable="growth_rate">
<listOfParameters>
<parameter id="Y_MIN" value="-inf"/>
<parameter id="LINEAR_CONSTANT" value="0.7"/>
<parameter id="Y_MAX" value="inf"/>
<parameter id="LINEAR_COEF" value="-0.1"/>
<parameter id="X_MIN" value="0.2"/>
<parameter id="X_MAX" value="2"/>
</listOfParameters>
</function>
3.3 Estimating portion of nonenzymatic protein per compartment
In RBA, the modelled proteins are involved in metabolic function or are part of a modelled cellular process (translation, chaperoning - this will depend on your particular model). However, not the entire protein pool will be reserved for such proteins - there are other, unmodelled, proteins which the cell also needs to
produce (the so-called maintenance or housekeeping proteins). The script nonenz_per_compartment.py and the accompanying configuration file nonenz_per_compartment.cfg enable the estimation of the portion of these proteins for all cellular compartments. Most of the configuration is identical as for the fraction of protein per compartment (see section 3.2).
Two additional files that need to be provided are:
[CategoryData]: Proteins with assigned functional categories. First column is expected to contain protein IDs, and one of the other columns the functional categories. The name of this column needs to be provided in thecat_columnparameter.[IsEnzymaticData]: a file describing which functional category is considered enzymatic (opposite of housekeeping). First column should contain a full list of functional categories, and one other column should containTRUEorFALSEvalues. The name of that column should be provided in theis_enzymatic_columnparameter.
3.4 Estimating the apparent catalytic rates of enzymes
In order to estimate the apparent catalytic rates of enzymes, you need to provide fluxomics and proteomics data. Fluxomics is used as constraints to determine the intracellular flux distribution using parsimonious FBA. Proteomics is used to estimate the concentration of metabolic enzymes and transporters. Apparent catalytc rates are then computed as the ratio between the flux and the enzyme or transporter concentration per metabolic reaction. Proteins need to have same identifiers as the ones used in the model. The configuration script has four fields:
-
[ProteinData]where you need to provide the path to the file containing the proteomics data, as well as the cell dry weight for the cell at that growth conditions. This is assuming that the proteomics data is given in copies per cell. If the data is already provided as a concentration in mmol per gram of cell dry weight, you can set the cell dry weight (cdw) parameter to 1. - [Flux data] where you need to provide the path to the fluxomics data. The first column is expected to contain one or more reaction IDs (from the model) separated by a comma. There are two additional columns you need to provide: upper bound and lower bound on the reactions, and the name of these columns needs to be supplied in the configuration file under
[Model] in which you need to provide paths to the original metabolic model in SBML format used for creation of the RBA model, as well as the path to the directory containing the XML files specifying the RBA model. You also need to provide a name of the biomass reaction you wish to use as the objective function in an FBA simulation (which is used for the calibration procedure).
[Output] where you specify the files in which the results of the estimation of apparent catalytic rates and of the predicted intracellular flux distribution will be stored.
ub_column and lb_column.
4. Details on the SBML requirements
Normally, RBApy should be compatible with any SBML models (SBML level 2 and 3) that have been generated using the protocol of Thiele & Palsson. "A protocol for generating a high-quality genome-scale metabolic reconstruction." Nature protocols 5.1 (2010): 93.". However, in practice, ambiguous information may be present, which can disturb or slow down the process of RBA model building.
4.1 Gene-association requirements
In RBA, one reaction is always catalyzed by an unique enzymatic complex. Therefore, isoenzymes, i.e. reactions that are catalyzed by several distinct enzymatic complexes, are duplicated. For instance, if one reaction R is catalyzed by two different enzymes, E1 and E2, then we introduce two reactions R1 and R2, catalyzed respectively by E1 and E2. The two enzymes have their own apparent catalytic rates kapp1 and kapp2.
During the parsing of the SBML file, RBApy parses the boolean rule of gene(s) associated to the reaction and duplicates the reaction automatically if necessary. RBApy can parse gene-association reactions that are annotated either in the field “note”, either using the fbc plugin with SBML level 3. However, sometimes, the boolean rule can be very complex, and thus difficult to parse. Therefore, RBApy assumes that the boolean relation is always “or”s of “and”s. Moreover, the words “or” and “and” must be written in lowercase letters.
The order of the gene(s) that are listed in the boolean rule is important. RBApy will automatically consider that the first gene encodes the first enzyme subunit, and so on. If this information has no impact for model simulation, it becomes important during model calibration (see section 3.4)
Empty fields in Gene-association will be interpreted as a diffusion reaction, meaning that no enzyme will be associated to the reaction. In contrast, any other character string will automatically be considered as a gene name. RBApy will try to match the gene name with a Uniprot entry. If the matching fails, then a default protein of average composition is created. The unknown gene name will be inserted in the file unknown_protein.tsv for manual curation (see section 2.3.3.7). Therefore, a reaction without a gene association may be catalyzed by an enzyme, then the user should insert any character strings such as “-” or “unknown_gene”.
4.2 External compartments
RBApy determines external metabolites from the SBML file using the following rules:
- All metabolites that end with a suffix listed in EXTERNAL_COMPARTMENTS as specified in the params.in file.
- All metabolites whose
boundaryConditionattribute is set totrue.
M -> or -> M),
the compartment is considered external: all the metabolites it contains are tagged as external.
For greater reliability, we advise to set either EXTERNAL_COMPARTMENTS in params.in or boundary conditions in the SBML.
In the RBA model, medium.tsv contains the concentrations of all external metabolites. These concentrations are used to define input fluxes through transporter enzymes. By default, they modulate transporter catalytic rates through Michaelis-Menten functions: the higher the concentration, the higher the import efficiency.
5. Miscellaneous
5.1 Decision variable IDs within RBApy
In genome scale metabolic reconstructions, it is customary to give "R_" prefixes to reaction IDs, and "M_" prefixes to metabolites. Cobrapy toolbox removes these prefixes, and they are also absent, for example, from the Escher maps flux visualization tool. RBApy retains these prefixes. Because of that, in some result export functions, it is possible to remove this prefix to make the data compatible with visualization tools. Apart from flux variables, RBApy also estimates enzyme abundances. Assuming that the reaction ID is R_reaction, a corresponding enzyme ID will be R_reaction_enzyme. Apart from reactions and enzymes, RBApy estimates concentrations of cell process macromolecular machines, such as ribosomes, chaperones, etc. These processes are defined in the processes.xml file, and their IDs are usually preceeded by "P_" prefix.
5.2 Isoenzymes
As described in section 4.1, more than one protein complex can be assigned to an enzymatic function.
In such cases, RBA will create as many reactions as there are protein complexes associated with it, and each flux and protein complex will
be a variable in the optimization procedure. For example, if in the metabolism file we find a reaction with
an ID Reac1 which is catalyzed by three different protein complexes, RBA will create three flux variables with IDs
Reac1, Reac1_2 and Reac1_3 and three enzyme variables, each one associated to a specific protein complex,
with IDs Reac1_enzyme, Reac1_2_enzyme and Reac1_3_enzyme.
In this new package version, RBApy also creates a mean RBA model pooling all isoenzymes catalyzing the same metabolic reaction into a single mean enzymatic complex.